Kafka Basic
Kafka Basic
Kafka 简介
Kafka是最初由Linkedin公司开发,是一个分布式、分s区的、多副本的、多订阅者,基于zookeeper协调的分布式日志系统(也可以当做MQ系统),常见可以用于web/nginx日志、访问日志,消息服务等等,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
主要应用场景是:日志收集系统和消息系统。
Kafka主要设计目标如下:
- 以时间复杂度为O(1)的方式提供消息持久化能力,即使对TB级以上数据也能保证常数时间的访问性能。
- 高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100K条消息的传输。
- 支持Kafka Server间的消息分区,及分布式消费,同时保证每个partition内的消息顺序传输。
- 同时支持离线数据处理和实时数据处理。
- 支持在线水平扩展
官方简介:http://kafka.apache.org/intro
Kafka架构:

存储机制:
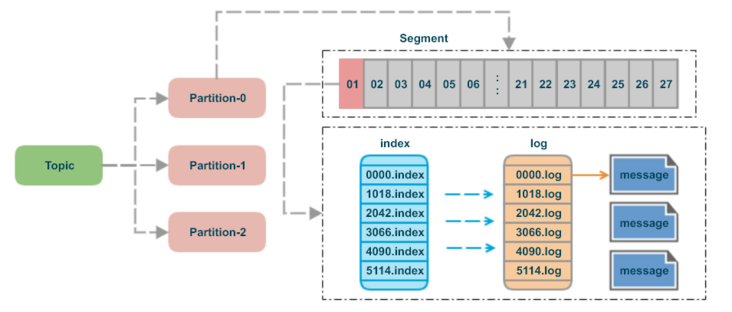
topic: 可以理解为一个消息队列的名字partition:为了实现扩展性,一个非常大的topic可以分布到多个 broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列segment:partition物理上由多个segment组成message:每个segment文件中实际存储的每一条数据就是messageoffset:每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中,partition中的每个消息都有一个连续的序列号叫做offset,用于partition唯一标识一条消息
Kafka 安装与部署
单机部署(single broker)
- 首先从官方下载站点获取所需版本的二进制包并解压缩:
wget http://apache.mirrors.hoobly.com/kafka/2.5.0/kafka_2.13-2.5.0.tgztar xf kafka_2.13-2.5.0.tgzcd kafka_2.13-2.5.0- 启动服务:
Kafka依赖于ZooKeeper服务器,可以使用 kafka 附带的脚本来启动单节点 ZooKeeper 实例:
> bin/zookeeper-server-start.sh config/zookeeper.properties现在,启动Kafka服务:
> bin/kafka-server-start.sh config/server.properties- 创建一个
topic:
# 创建一个单节点,单分区名为test的topic> bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 1 --partitions 1 --topic test查看当前运行的topic有哪些:
> bin/kafka-topics.sh --list --bootstrap-server localhost:9092test- 发送一些信息:
Kafka带有一个命令行客户端,它将从文件或标准输入中获取输入,并将其作为消息发送到 Kafka 集群。默认情况下,每行将作为单独的消息发送:
# 使用以下命令将生产者的信息发往broker> bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic testhello kafkakafka# kafka-console-producer.sh --broker-list node01:9093,node01:9094,node01:9095 --topic wzxmt- 启动一个消费者
consumer:
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning# 可以看到生产者发出的信息hello kafkakafka# kafka-console-consumer.sh --bootstrap-server node01:2181 --from-beginning --topic wzxmt集群部署(Mutil-broker)
因手头资源有限,故用单台主机模拟集群。
- 首先,为每一个
broker创建一个配置文件:
> cp config/server.properties config/server-1.properties> cp config/server.properties config/server-2.properties> cp config/server.properties config/server-3.properties分别修改这些文件的以下属性:
# --------- config/server-1.properties --------------broker.id=1# 监听listeners=PLAINTEXT://:9091 # 注意:早些版本的Kafka用的时 port 字段。。# 日志目录log.dirs=/data/kafka/logs-1# 配置zookeeper的连接,当zookeeper为集群时使用# zookeeper.connect=node01:2181
# --------- config/server-2.properties --------------broker.id=2listeners=PLAINTEXT://:9092log.dirs=/data/kafka/logs-2# zookeeper.connect=node02:2181
# --------- config/server-3.properties --------------broker.id=2listeners=PLAINTEXT://:9093log.dirs=/data/kafka/logs-3# zookeeper.connect=node03:2181为其创建日志文件夹,mkdir -p /data/kafka/{logs-1,logs-2,logs-3}
- 分别启动这三个 broker:
> bin/kafka-server-start.sh config/server-1.properties &...> bin/kafka-server-start.sh config/server-2.properties &...> bin/kafka-server-start.sh config/server-3.properties &...- 创建
topic(指定副本数量为3):
> bin/kafka-topics.sh --create --bootstrap-server localhost:9092 --replication-factor 3 --partitions 1 --topic my-replicated-topic查看所有的topic列表信息:
> bin/kafka-topics.sh --list --bootstrap-server localhost:9092查看特定 topic 的详细信息:
[root@master kafka_2.13-2.5.0]\# bin/kafka-topics.sh --describe --bootstrap-server localhost:9092 --topic my-replicated-topicTopic: my-replicated-topic PartitionCount: 1 ReplicationFactor: 3 Configs: segment.bytes=1073741824 Topic: my-replicated-topic Partition: 0 Leader: 2 Replicas: 2,1,3 Isr: 2,1,3- 发送一些信息到
topic:
> bin/kafka-console-producer.sh --bootstrap-server localhost:9092 --topic my-replicated-topic...hello kafkakafka消费这些信息:
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --from-beginning --topic my-replicated-topic...hello kafkakafka:information_source: 测试leader宕掉:
[root@master kafka_2.13-2.5.0]\# ps aux | grep server-2.propertiesroot `32410` 9.1 18.9 4025076 353104 pts/6 Sl 02:48 0:16 ...> kill -9 32410leader节点已切换到observer之一,并且该节点不再位于同步副本集中:
[root@master kafka_2.13-2.5.0]\# bin/kafka-topics.sh --describe --bootstrap-server localhost:9091 --topic my-replicated-topicTopic: my-replicated-topic PartitionCount: 1 ReplicationFactor: 3 Configs: segment.bytes=1073741824 Topic: my-replicated-topic Partition: 0 Leader: 3 Replicas: 2,3,1 Isr: 3,1但是此前发送的信息依然存在:
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9091 --from-beginning --topic my-replicated-topic...hello kafkakafka附:server.properties 参数说明
#broker的全局唯一编号,不能重复,只能是数字broker.id=1#此处的host.name为本机IP(重要),如果不改,则客户端会抛出:Producerconnection to node01:9092 unsuccessful 错误!# host.name=10.0.0.11#用来监听链接的端口,producer或consumer将在此端口建立连接# port=9092# 监听listeners=PLAINTEXT://:9091#处理网络请求的线程数量num.network.threads=3#用来处理磁盘IO的线程数量num.io.threads=8#发送套接字的缓冲区大小socket.send.buffer.bytes=102400#接受套接字的缓冲区大小socket.receive.buffer.bytes=102400#请求套接字的缓冲区大小socket.request.max.bytes=104857600#kafka消息存放的路径(持久化到磁盘)log.dirs=/data/kafka/logs#topic在当前broker上的分片个数num.partitions=2#用来恢复和清理data下数据的线程数量num.recovery.threads.per.data.dir=1#segment文件保留的最长时间,超时将被删除log.retention.hours=168#滚动生成新的segment文件的最大时间log.roll.hours=168#日志文件中每个segment的大小,默认为1Glog.segment.bytes=1073741824#周期性检查文件大小的时间log.retention.check.interval.ms=300000#日志清理是否打开log.cleaner.enable=true#broker需要使用zookeeper保存meta数据zookeeper.connect=node01:2181,node02:2181,node03:2181#zookeeper链接超时时间zookeeper.connection.timeout.ms=6000#partion buffer中,消息的条数达到阈值,将触发flush到磁盘log.flush.interval.messages=10000#消息buffer的时间,达到阈值,将触发flush到磁盘log.flush.interval.ms=3000#删除topic需要server.properties中设置delete.topic.enable=true否则只是标记删除delete.topic.enable=true#延迟初始使用者重新平衡的时间(生产用3)group.initial.rebalance.delay.ms=0#broker能接收消息的最大字节数message.max.bytes=2000000000#broker可复制的消息的最大字节数replica.fetch.max.bytes=2000000000#消费者端的可读取的最大消息fetch.message.max.bytes=2000000000不同节点之间只需要修改server.properties 的 broker.id即可。