临时复习用(很乱)
链接两个独立的系统或者软件,即使他们有着不同的接口,但是通过中间件都仍能实现信息交换. 常见的中间件有:Tomcat/JBoss(web服务器)/Kfaka/Redis/influxdb/zookeeper/RabbitMQ
链路追踪:可以帮助理解系统行为、用于分析性能问题的工具,以便发生故障的时候,能够快速定位和解决问题。
SkyWalking 核心模块介绍: SkyWalking采用组件式开发,易于扩展,主要组件作用如下:
-
Skywalking Agent:链路数据采集tracing(调用链数据)和metric(指标)信息并上报,上报通过HTTP或者gRPC方式发送数据到Skywalking Collector
-
Skywalking Collector : 链路数据收集器,对agent传过来的tracing和metric数据进行整合分析通过Analysis Core模块处理并落入相关的数据存储中,同时会通过Query Core模块进行二次统计和监控告警
-
Storage: Skywalking的存储,支持以ElasticSearch、Mysql、TiDB、H2等主流存储作为存储介质进行数据存储,H2仅作为临时演示单机用。
-
SkyWalking UI: Web可视化平台,用来展示落地的数据,目前官方采纳了RocketBot作为SkyWalking的主UI
lvs的三种工作模式,dr直接路由模式,tun隧道模式,nat模式
- nat: 客户端发送数据包到lvs负载均衡器,在负载均衡器上将数据包的目的ip换为后端rs的ip,rs接受数据包并作出相应将返回的数据包发送给负载均衡器,负载均衡器将SIP替换成自己的ip,最后将响应的数据包发送给客户端
优点是:集群中的物理服务器可以使用任何支持TCP/IP操作系统,只有负载均衡器需要一个合法的IP地址。
缺点:扩展性有限。当服务器节点(普通PC服务器)增长过多时,负载均衡器将成为整个系统的瓶颈。
因为所有的请求包和应答包的流向都经过负载均衡器。当服务器节点过多时
大量的数据包都交汇在负载均衡器那,速度就会变慢!
- tun: 客户端将数据包发送给负载均衡器,在负载均衡器上将数据包的目的ip换为后端rs的ip,后端rs服务器收到数据包之后直接解包然后处理完将响应的数据包返回给客户端。
优点是:将数据包直接返回给客户端,这样负载均衡器就不再是性能瓶颈,大大提升了效率,
缺点是:每台主机都得支持ip tunnel隧道,并且都得有一个合法的ip
- dr: 负载均衡器与后端RS用同一个IP地址,通过ARP进行请求响应,所有RS对本身这个IP的ARP请求保持静默也就是说,网关会把对这个服务IP的请求全部定向给DR,而DR收到数据包后根据调度算法,找出对应的RS,把目的MAC地址改为RS的MAC(因为IP一致),并将请求分发给这台RS这时RS收到这个数据包,处理完成之后,由于IP一致,可以直接将数据返给客户。则等于直接从客户端收到这个数据包无异,处理后直接返回给客户端。
由于负载均衡器要对二层包头进行改换,所以负载均衡器和RS之间必须在一个广播域
缺点:要求负载均衡器的网卡必须与物理网卡在一个物理段上。
lvs: 只支持4层,无流量产生,转发效率高、性能好,不会受大流量的影响,应用范围较广,配置简单;缺点是只能工作在第四层、所以无法实现应用层的一些动静分离、根据url正则匹配等操作; nginx:工作在7层4层,正则比haproxy要强大、配置更加灵活,网络依赖小、配置简单方便、nginx不仅仅是负载均衡器,还可以做一些其他的事情,比如反向代理、缓存、web服务器等、处理静态页面效率高;缺点是不支持url健康检测、只支持简单的ip:port 探活,支持的协议少、只能支持http和email haproxy:7层4层,haproxy支持的负载均衡算法多,haproxy支持的后端软件比nginx要多,比如可以对mysql的读来进行负载均衡,session和cookie方面要比nginx优秀。
中小企业选择haproxy和nginx,大型企业一般并发量高,选择lvs.
kubernetes网络模型:
- calico: 两种模式:IPIP-tunnel隧道 和 BGP网关,此外还有一个cross-subnet模式,在该模式下,相同子网中使用BGP模式,不同子网之间使用IPIP隧道模式.
calico的ip in ip模式,创建一个名为tunl0的网卡,并设置相关路由
- flannel:
以docker为例,原容器向目标容器发送数据包,如果都是brige网络模式的话,会先将数据包发送个docker0虚拟网桥,然后虚拟网桥将收到的数据转发给flannel-1虚拟网卡进行处理,随后flanneld程序将flannel-1中的数据包进行封装,将数据包封装成二层以太包,即添加MAC地址,如下: 源容器:flannel-1的虚拟网卡mac地址 目的容器:flannel-1的虚拟网卡mac地址
最后借助linux内核对数据进行再次封装,这样才能使源容器的数据传输到目的容器。
iNode: inode是文件的元数据,包含属主属组,文件大小,权限等信息,真正存放数据的是block块,一个块又有8个sector也就是扇区组成,一个扇区最常见的大小为4kb。 而文件名是存放于目录之中,Linux文件系统内部以inode来标识文件,在终端使用stat命令可以查看文件的inode元数据信息,使用ls- i查看文件的Inode编号.
系统打开文件的流程:首先系统会根据文件名查找inode号码,根据inode记录的信息校验当前用户是否有该文件的相关权限,如果没有,那就拜拜,如果有就通过inode号码获得block,根据inode信息找到文件所在的block,最后读出数据。
inode的存储也会消耗掉磁盘空间,可以通过df -i查看当前磁盘inode的使用和总数剩余情况。
注意点:移动文件或者修改文件名不会影响inode号码,当打开一个文件之后,系统就不会再考虑文件名称
redis集群如何保证高可用:https://blog.51cto.com/u_15351425/3741065
redis的持久化存储有RDB实现,redis会定期将数据保存到一个RDB文件中,并在启动时自动加载该文件,恢复之前保存的数据。 另外一种是AOF,redis会将每一个写请求写入到一个文件当中去,在redis重启的时候会自动读入aof文件,并重新执行一遍。
重点:redis的主从架构和mysql类似,可以做读写分离,主节点主要用于写入数据,从节点用于读取数据,当有高并发数据读取,有压力时,可以横向水平扩容slave从节点以应对高并发场景。
第一次,slave连接上master时,会发送psync命令全量同步master节点上的数据, 同步流程大致是:master生成一个线程,将数据存入rdb中,并将新的请求缓存到内存中,主节点写入完毕rdb文件之后,将rdb文件发送给从节点,从节点将数据同步到硬盘,然后主节点又将内存中新写入的那些请求数据发送给slave继续同步。
如果master和slave节点之间因网络发生断连,当重新连接时,master节点会从自己的backlog中读取部分数据,让slave进行增量更新,增量更新的依据是:slave节点发送的offset偏移量。
哨兵:监控master,slave的工作状态,如果master节点挂了,那么将自动转移到slave节点上,,如果某个节点挂了,哨兵也可以通知管理员进行处理
slave抢占master依据,slave的优先级,复制offset偏移
数据分区的概念,将数据划分到各个节点,根据哈希算法进行分区。
哨兵+主从架构并不能保证数据不会丢失,但是可以保证集群的高可用性。
kafka: topic---》partition---》segmant---》index---》log---》message leader --- follower/Broker 生产者消费者模型,
生产者异步生产消息,生产者向kafka发送消息,kafka会立即回复,但是并不保证消息的发送已经完成,可能会出现网络抖动的情况导致生产者的消息根本没有发送到brocker
有offset概念,对于消费者来说,就是消费到topic分区的那个位置。
kafka如何保证消息不丢失:先消耗消息,再更新offset来保证消息不丢失。
kafka依赖zookeeper(集群)存储broker,topic等信息
zookeeper:需要安装java环境, 分布式数据一致性方案。
用途:锁,队列,配置管理(一旦配置发生变化,zk就会发送消息通知给其他服务器),命名服务(因为zookeeper是目录结构,那么会非常容易创建出一个全局唯一的path), 有几种节点类型:7种, 持久、临时:临时节点对于持久节点来说,会随着客户端会话的结束而被删除,用于特殊场景,如分布式锁的释放,健康检查等。
持久顺序、临时顺序:对于来自客户端的每个更新请求,ZooKeeper 都会分配一个全局唯一的递增编号,这个编号反应了所有事务操作的先后顺序,应用程序可以使用 ZooKeeper 这个特性来实现更高层次的同步原语。该节点可以是临时的也可以是持久的。
数据类型:层次化目录结构 +少量数据
选举:用的是根据算法的投票机制,票数都就是leader,leading和following状态,服务器id越大,在选举时的权重越大, 角色:leader领导者、follower跟随者、observer观察者、client客户端 leader:负责投票的发起和决议,更新系统状态,处理事务请求。 follower跟随者:参与投票,接收客户端请求,处理非事务请求并返回结果,转发事务请求给leader。 observer观察者:不参与投票过程,只同步leader状态,为了扩展系统,提高读写速度。也接收客户端请求,处理非事务请求并返回结果,转发事务请求给leader。 client请求发送方
zookeeper的读性能随节点数量的增加,读性能增加,写性能下降,因此限制了节点数量。
zookeeper满足CAP理论中的C一致性和P分区容忍性,牺牲了A高可用性,并且znode的存储是在内存,因此zookeeper一般只用于存储配置信息。
zookeeper的主动模式和被动模式,主动模式可以实现agent节点自动向server节点汇报,这样就减轻了server端的压力,
mysql主从同步,master节点将变更的数据存放于bin-log中,slave节点会开启一个io线程读master节点的bin-log并存放于从节点的relay-log中去,另外还会开一个sql线程,将数据读取或者回放到从节点以达到主从同步。
两常用引擎的对比: INNODB会支持一些关系数据库的高级功能,如事务功能和行级锁,MYISAM不支持。 MYISAM的性能更优,占用的存储空间少。
undo log: 保证事务中的原子性,用于事务回滚等 redo log: 保证事务的持久性,用于掉电恢复等 binlog: 数据备份和主从复制
mysql索引类型:主键索引,唯一索引,复合索引,前缀索引
CPU或者load过高排查:
情况1:CPU高、Load高 通过top命令查找占用CPU最高的进程PID; 通过top -Hp PID查找占用CPU最高的线程TID; 对于java程序,使用jstack打印线程堆栈信息; 通过printf %x tid打印出最消耗CPU线程的十六进制; 在堆栈信息中查看该线程的堆栈信息;
情况2:CPU低、Load高 top-iostat-sar,ps 通过top命令查看CPU等待IO时间,即%wa; 通过iostat -d -x -m 1 10查看磁盘IO情况;(安装命令 yum install -y sysstat) 通过sar -n DEV 1 10查看网络IO情况; 通过如下命令查找占用IO的程序;
kube-proxy中使用iptables和ipvs的区别: 当集群中服务量较少,1000,iptables是个不错的选择,有良好的兼容性和网络策略的实现, ipvs适合大集群,其处理速度和效率与集群大小无关,提供更好的扩展性和功能性,ipvs有着比iptables更多的负载均衡算法,ipvs支持健康状态检查。
kube-proxy 通过 iptables 处理 Service 的过程,其实需要在宿主机上设置相当多的 iptables 规则。而且,kube-proxy 还需要在控制循环里不断地刷新这些规则来确保它们始终是正确的。不难想到,当你的宿主机上有大量 Pod 的时候,成百上千条 iptables 规则不断地被刷新,会大量占用该宿主机的 CPU 资源,甚至会让宿主机“卡”在这个过程中。所以说,一直以来,基于 iptables 的 Service 实现,都是制约 Kubernetes 项目承载更多量级的 Pod 的主要障碍。
IPVS 模式的工作原理,其实跟 iptables 模式类似。当我们创建了前面的 Service 之后,kube-proxy 首先会在宿主机上创建一个虚拟网卡(叫作:kube-ipvs0),并为它分配 Service VIP 作为 IP 地址。接下来,kube-proxy 就会通过 Linux 的 IPVS 模块,为这个 IP 地址设置三个 IPVS 虚拟主机,并设置这三个虚拟主机之间使用轮询模式 (rr) 来作为负载均衡策略
netstat -na | awk ’/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}’ 以用来分析tcp各种连接的连接数
redis默认支持16个数据库,通过修改配置文件可以修改其上限
Prometheus的联邦模式:prometheus的分布式类似于nginx的负载均衡模式,主节点配置文件可以配置从节点的地址池,主节点只要定时向从节点拉取数据即可,主节点的作用就是存贮实时数据,并提供给grafana 使用。而从节点作用就是分别从不同的各个采集端中抽取数据,可以实现分机器或者分角色。这种由一个中心的prometheus负则聚合多个prometheus数据中的监控模式,称为prometheus联邦集群。
关键词:promQL聚合查询语言,可以用来配置报警规则;pushgateway,prom的可选中间件,但是对场景要求比较高,适合于prom部署于其他机房或者云平台,监控的主机又在本地局域网当中,劣势很明显,pushgateway会造成单点故障,导致监控数据丢失。 内置时序数据库TSDB,基于时间序列的key,value键值对,提供本地和分布式存储 target概念,endpoint,metrics 生态相关:altermanager、consul注册中心(服务发现、服务注册、服务发布等)
可以监控哪些数据?以redis为例: redis当前主机服务器的基本信息,CPU,内存、磁盘使用状况等。 redis的服务状态; RDB、AOF日志的监控 key命中的数量和key数量的监控
prom收集的metrics数据源: exporter:指标暴露器,如果监控端的应用不支持prom兼容的格式输出,那么就是用各种exporter来将其转换成prom格式的数据并等待prom来收集,被动模式, 第二种是应用本身有数据收集,监控的功能,并暴露一个metrics等待prom进行日志收集即可. 第三种是pushgateway,周期性主动收集metrics信息
如何防止报警轰炸: prom本身可以生成报警信息,但是无法直接向第三方提供报警,如钉钉,企微,短信,各种im软件等,需要使用altermanager来进行报警,altermanager可以实现报警信息的收敛,比如去重、静默、可以有效的防止报警爆炸。
zabbix对比prometheus:zabbix支持的节点数有限,最多支持10000个节点,当节点数过多时,可能会导致报警不及时等情况发生,而prometheus可以支持大集群,而且响应速度很快,zabbix更适用于物理机,prom更适合云环境的监控,zabbix有着成熟的webui界面,更容易上手。
PostgreSQL 模式(SCHEMA)可以看着是一个表的集合。
一个模式可以包含视图、索引、数据类型、函数和操作符等。
CREATE SCHEMA myschema.mytable (
bash shell 相关
if [ condition ]; then
# dosomething
else
# do someghing else
fi
其中condition的,-z 判断变量是否为空,-n判断变量是否非空
for fruit in ”${fruits[@]}“用于遍历数组
flock文件锁,可以当文件正在执行时,禁止其他人执行
until command;do command;done while command;do command;done for name in xxx yyy zzz;do command;done for (( expr1; expr2; expr3 ));do command;done
if command;then command; elif command; then else command; fi
case $word in xxx | yy ) echo … zzz ) echo *) echo… esac
func() {
}
数字运算
val=expr $b % $a
if [ $a == $b ]
if [ $a -eq $b ]
bool运算符
if [ $a -lt 100 -o $b -gt 100 ] 逻辑运算符 && ||
字符串运算符
= != -z字符串长度是否为零,-n
$(( )) 的功能是进行算术运算,如c=$(($a * $b)) $[ ] 的功能与 $(( )) 一样,都是用于算术运算。 for ((i = 0; i < 10; i++)),高级运算 [ ]用于条件测试,例子如上 [[ ]]用于高级字符串对比
ansible 注册变量,可以让下一个task使用上一个task的值,set_facts,register模块 ansible设置并行数量---forks = 1,默认为5,滚动更新,可以让主机顺序执行, 常用模块:copy,handlers、git、fetch、fail、except、apt、systemd、yum、command等 ansible playbook大致结构:
- host: remote_user become
- tasks: -name
docker使用到的技术: linux内核的命名空间、虚拟网卡等 实现了文件系统、主机名、进程、网络接口的隔离 cgroup实现了资源之间的隔离与限制,比如CPU、内存、网络带宽等资源
docker镜像采用了叠加overlay存储,实质上是一个压缩包。
dockerfile:FROM(多阶段构建FROM … as …)、USER、LABEL、ARG、EXPOSE、ENV、ADD、COPY(COPY ---from name …多阶段构建)、ENTRYPOINT、CMD(将可变参数写到CMD里面,配合entrypoint使用)、VOLUME,多阶段构建 copy add区别:copy可用于多阶段构建,add可以传入压缩包,并自动解压,而且可以传入url
Dockerfile 是用于定义 Docker 镜像构建步骤的文件,包含了一系列的指令(instruction)和参数。
以下是 Dockerfile 中常见的指令和参数:
指令:
- FROM:指定基础镜像。
- RUN:在镜像中执行命令。
- CMD:设置容器启动后默认执行的命令及其参数。
- ENTRYPOINT:设置容器启动后默认执行的命令。
- COPY:将文件或目录复制到容器中。
- ADD:将文件或目录复制到容器中,并且支持自动解压缩功能。
- ENV:设置环境变量。
- ARG:设置构建时的参数,类似于函数中的参数
- EXPOSE:指定容器监听的端口。
- VOLUME:指定容器挂载的数据卷。
- USER:设置容器启动时的用户。
- WORKDIR:设置容器的工作目录。
- LABEL:为镜像添加元数据,如作者、描述、版本等。
- ONBUILD:在当前镜像的基础上构建其他镜像时执行的命令。
参数:
- —no-cache:构建过程中不使用缓存。
- —rm:在镜像构建完成后删除所有中间容器。
- —quiet,-q:以安静模式构建,只输出镜像 ID。
- —pull:在构建时尝试从远程仓库拉取最新的版本。
以下是Docker Compose的所有关键字及其说明:
- version:指定所使用的compose文件版本。
- services:定义组成应用的各个服务,包括镜像、容器设置和服务依赖关系。
- build:指定在构建镜像时所需的配置文件路径。
- image:定义要使用的已构建好的镜像名称和标签。
- container_name:定义所创建容器的名称,避免系统自动命名。
- ports:定义容器端口与主机端口之间的映射。
- volumes:定义要挂载到容器内部的卷。
- environment:为容器设置环境变量,可覆盖镜像内的变量。
- networks:定义容器需要连接的网络,使得不同容器之间可以相互通讯。
- depends_on:定义服务之间的依赖关系。
- restart:定义容器失效后是否自动重启。
以上是Docker Compose的所有关键字及其说明。
pod生命周期: 挂起pending 运行中 成功 失败 未知,使用就绪性和存活性探针
数据的备份: 热备,冷备,双活 热备:成本较高,恢复时间较短,当主数据中心出现异常时,会自动切换到备用数据中心 冷备:操作简单,恢复时间长,手动或者定期执行备份,当出现异常时,需要人工手动切换数据中心 双活:主备数据中心互为主备,运维成本较高,恢复时间很短,
异地双活或者多活,如何保证数据的一致性,解决方案有zookeeper/实现paxos
ELFK大致流程?组成及功能?
可选项kafka,由于elfk的局限性,当每秒的数据量太大,logstash承受不了,会导致日志收集出现文件,虽说可以增加Logstash的节点做成集群来提高每秒的处理速度,但是仍需要考虑es无法承受这么大量的日志瞬时写入,所以引入kafka做消息队列,进行缓存. kafka一般与zookeeper共同使用。
filebeat -> kafka -> logstash -> es -> kibana/Grafana
- filebeat配置中添加kafka地址,以及topic的名称
- logstash在input配置段中读取日志数据,类型就是kafka,指定topic,数据类型,以及消费方式。 数据处理output,指定es地址
beats采集到数据, 将其传递给 logstash过滤出需要的信息, 再将其传递给elasticsearch进行存储检索等流程,并将结果传递给kibana进行图形化展示 其中beats与logstash之间、logstash与elasticsearch之间都可能会存在性能瓶颈, 适当增加消息中间件(kafka或redis)有利于整体稳定 elasticsearch作为elk的核心, 可以分布式部署多个节点, 组成集群。
各组件用途: beats 用于数据采集, 根据采集对象的不同, 细分出了8个子模块, 最常用的是filebeat, 即文件与目录的采集,常用来采集各种业务的日志信息 logstash 主要用于数据筛选,日志分流, Logstash 过滤器能够解析各个事件,识别已命名的字段以构建结构,并将它们转换成通用格式,以便进行后续分析。 elasticsearch 简而言之就是一款分布式、高扩展、高实时的搜索与数据分析引擎 kibana 主要用于数据成果的图形化展示, 自带很多标准模板以供使用, 例如nginx模块等.基本满足使用需求, 但是有些细节之处仍然需要修改
prom - altermanager 配置相关? prometheus 配置告警表达式,定期检查是否触发阈值,如果触发阈值,那么就发送HTTP告警给alertmanager,alertmanager再通过邮件,脚本或者webhhook发送给第三方im软件。
grafana权限控制,可以使用team团队组实现,单独为组设置读写权限。
😈nginx相关:
nginx访问ip数量, cat access.log| awk | uniq -c | sort -n
nginx location匹配顺序:精确匹配=,前缀正则匹配^,(区分大小写的正则匹配,不区分大小写的正则匹配~*),前缀匹配/foo/bar/…
proxy_paas最后的那个/的影响:(location /foo/)加/代表绝对路径,也就是访问的时候访问到/test.html,如果不加则代表(location /foo/)/foo/test.html,另外如果proxy_paas中也加路径的话,比如proxy_paas http://sdfs.com/foo,那么最后访问时不加/则访问footest.html,如果加则访问foo/test.html.
自建ca,与自签证书概括流程 ca:生成私钥文件,生成x509证书文件 客户端:生成私钥文件,用私钥文件生成证书请求文件csr,将证书请求文件发送到自建ca主机,ca主机对csr文件进行证书签署,签署完毕之后生成.pem或者.crt证书文件,最后回传给客户端即可使用.
tcp、udp区别: tcp面向连接,进行数据传输之前需要建立连接,udp不需要连接,直接可以传输数据。 tcp是一对一个两点服务,udp可以一对多,多对多,一对一服务。 tcp是可靠传输,保证数据的完整性,不丢失,不重复,udp不保证可靠交付数据。 tcp有着拥塞和流控机制,保证数据传输的安全性,udp则没有,即时网络拥堵,也可以保证速率。 tcp头部开销大,udp首部固定8字节,开销较少。 tcp是流式传输,udp是一个个包传输。
tcp用于可靠性交付服务,用途ftp、http、https、等对数据可靠性较强的服务, udp适合DNS、SNMP、视频音频im软件等。
TCP/UDP OSI七层模型:每一层协议及作用
应用层: HTTP、FTP、Telnet、DNS、SMTP等,应用层是工作在操作系统中的用户态,传输层及以下则工作在内核态。 传输层: TCP 和 UDP传输协议,传输层中的报文会带有端口号, 网络层: IP 协议,IP 协议会将传输层的报文作为数据部分,再加上 IP 包头组装成 IP 报文,如果 IP 报文大小超过 MTU(以太网中一般为 1500 字节)就会再次进行分片,得到一个即将发送到网络的 IP 报文 IP地址的网络号和主机号。 网络接口层:生成了 IP 头部之后,接下来要交给网络接口层(Link Layer)在 IP 头部的前面加上 MAC 头部,并封装成数据帧(Data frame)发送到网络上。MAC 头部是以太网使用的头部,它包含了接收方和发送方的 MAC 地址等信息,我们可以通过 ARP 协议获取对方的 MAC 地址。
所以说,网络接口层主要为网络层提供「链路级别」传输的服务,负责在以太网、WiFi 这样的底层网络上发送原始数据包,工作在网卡这个层次,使用 MAC 地址来标识网络上的设备。
网络接口层的传输单位是帧(frame),IP 层的传输单位是包(packet),TCP 层的传输单位是段(segment),HTTP 的传输单位则是消息或报文(message)。但这些名词并没有什么本质的区分,可以统称为数据包。
tcp三次握手: 简单概括:客户端发送syn给服务器端,服务器端返回ack和syn数据包,客户端发送一个ack包给服务器端,以此建立连接。 ( https://cdn.xiaolincoding.com/gh/xiaolincoder/ImageHost4/%E7%BD%91%E7%BB%9C/TCP%E4%B8%89%E6%AC%A1%E6%8F%A1%E6%89%8B.drawio.png 一开始,客户端和服务端都处于 CLOSED 状态。先是服务端主动监听某个端口,处于 LISTEN 状态 客户端会随机初始化序号(client_isn),将此序号置于 TCP 首部的「序号」字段中,同时把 SYN 标志位置为 1 ,表示 SYN 报文。接着把第一个 SYN 报文发送给服务端,表示向服务端发起连接,该报文不包含应用层数据,之后客户端处于 SYN-SENT 状态。 服务端收到客户端的 SYN 报文后,首先服务端也随机初始化自己的序号(server_isn),将此序号填入 TCP 首部的「序号」字段中,其次把 TCP 首部的「确认应答号」字段填入 client_isn + 1, 接着把 SYN 和 ACK 标志位置为 1。最后把该报文发给客户端,该报文也不包含应用层数据,之后服务端处于 SYN-RCVD 状态 客户端收到服务端报文后,还要向服务端回应最后一个应答报文,首先该应答报文 TCP 首部 ACK 标志位置为 1 ,其次「确认应答号」字段填入 server_isn + 1 ,最后把报文发送给服务端,这次报文可以携带客户到服务器的数据,之后客户端处于 ESTABLISHED 状态。 服务器收到客户端的应答报文后,也进入 ESTABLISHED 状态。。 )
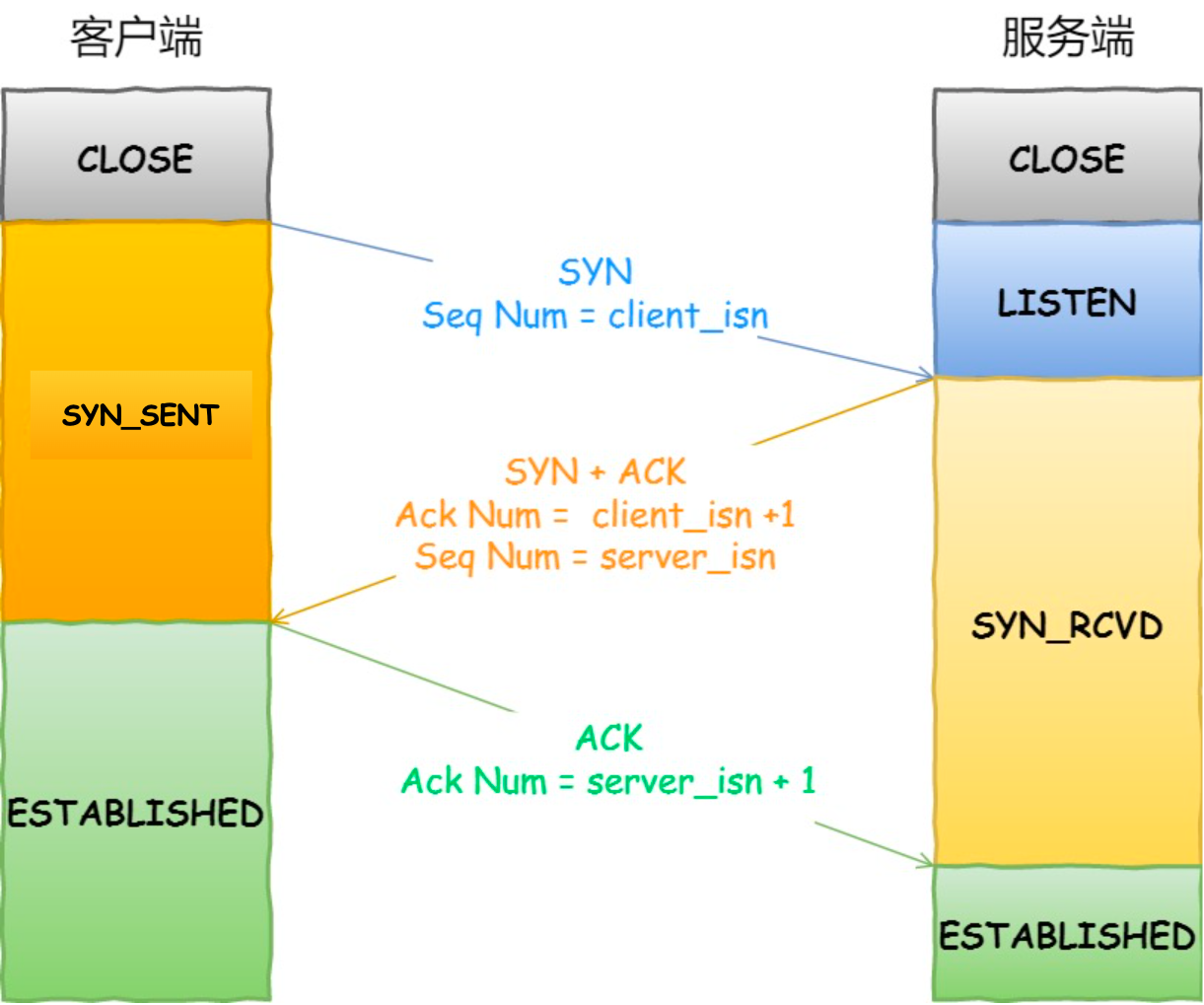{kind=link}
time_wait的作用:保证连接正常关闭,保证因为网络原因迟到的数据包能够接受并正常处理完成,或者丢弃掉不影响接下来新连接的建立。
四次挥手:客户端发送fin给服务器端已关闭连接,服务器端发送ack确认,并进入close_wait状态,客户端收到之后,进入fin_wait2状态,服务器端此后没有数据发送给客户端,服务器端会发送一个fin关闭服务器端到客户端的连接,客户端收到回复之后回复ack,服务器端收到后关闭连接,然后立即进入closed状态,客户端等待2msl最大生命周期之后,也进入closed状态。 ( https://imgconvert.csdnimg.cn/aHR0cHM6Ly9jZG4uanNkZWxpdnIubmV0L2doL3hpYW9saW5jb2Rlci9JbWFnZUhvc3QyLyVFOCVBRSVBMSVFNyVBRSU5NyVFNiU5QyVCQSVFNyVCRCU5MSVFNyVCQiU5Qy9UQ1AtJUU0JUI4JTg5JUU2JUFDJUExJUU2JThGJUExJUU2JTg5JThCJUU1JTkyJThDJUU1JTlCJTlCJUU2JUFDJUExJUU2JThDJUE1JUU2JTg5JThCLzMwLmpwZw?x-oss-process=image/format,png 客户端打算关闭连接,此时会发送一个 TCP 首部 FIN 标志位被置为 1 的报文,也即 FIN 报文,之后客户端进入 FIN_WAIT_1 状态。 服务端收到该报文后,就向客户端发送 ACK 应答报文,接着服务端进入 CLOSED_WAIT 状态。 客户端收到服务端的 ACK 应答报文后,之后进入 FIN_WAIT_2 状态。 等待服务端处理完数据后,也向客户端发送 FIN 报文,之后服务端进入 LAST_ACK 状态。 客户端收到服务端的 FIN 报文后,回一个 ACK 应答报文,之后进入 TIME_WAIT 状态 服务器收到了 ACK 应答报文后,就进入了 CLOSED 状态,至此服务端已经完成连接的关闭。 客户端在经过 2MSL 一段时间后,自动进入 CLOSED 状态,至此客户端也完成连接的关闭。 你可以看到,每个方向都需要一个 FIN 和一个 ACK,因此通常被称为四次挥手。 )
主动发起关闭连接的一方,才会有 TIME-WAIT 状态。
需要 TIME-WAIT 状态,主要是两个原因:
防止历史连接中的数据,被后面相同四元组的连接错误的接收; 保证「被动关闭连接」的一方,能被正确的关闭;
TIME_WAIT 等待 2 倍的 MSL,比较合理的解释是: 网络中可能存在来自发送方的数据包,当这些发送方的数据包被接收方处理后又会向对方发送响应,所以一来一回需要等待 2 倍的时间。
mongodb分片,简单来说,就是将数据分割到不同的服务器上,减少资源消耗,mongodb有自己的分片机制,简单配置即可.
kubernetes pod创建过程:通过kubectl,dashboard或者其他api客户端将pod spec清单文件提交给apiserver,apiserver收到请求之后,将相关信息写入etcd中,写入完成之后将结果返回给客户端, kubernetes上的所有组件都通过watch机制跟踪apiserver上的变化, scheduler通过watch机制发现apiserver创建了pod对象但是没有绑定到任何工作节点, 然后scheduler通过调度机制,资源、标签选择器或者亲和度算法来将pod调度到合适的节点上,并将调度的结果返回给apiserver, apiserver随后就将调度信息写入到etcd当中,并向客户端反应此次调度的节点信息, pod被调度到目的节点kubelet发现是自己,就会通过cri创建对应的容器,并将pod的状态返回给apiserver, apiserver收到pod的状态信息之后,将其写入到etcd中。
pod一直处于pending状态?目的工作节点资源不够,没有符合标签选择器的节点,没有容忍,scheduler异常等。
pipeline中的Jenkinsfile:
分为声明式和脚本式编码:
声明式pipeline,官方鼓励声明式编程模型,比较适合没有编程经验的初学者。
脚本式pipeline,是基于groovy的DSL语言实现的,为Jenkins用户提供了大量的灵活性性和可扩展性,如果脚本中有大量的逻辑处理则推荐使用。
脚本式pipeline只支持stage,像stages 、steps更细致的阶段划分则不支持,如果要在声明式中加入循环的逻辑的话,那么就需要使用script进行使用,而脚本式则不需要。
pipeline {agent、stages、stage、sh、when{branch}、environment、post}
node{…}
示例:https://gist.github.com/merikan/228cdb1893fca91f0663bab7b095757c
22:rabbitMQ 和 kafka的区别
RabbitMQ:用于实时的,对可靠性要求较高的消息传递上。以broker为中心,有消息的确认机制, 支持消息的可靠的传递,支持事务,不支持批量操作,存储可以采用内存或硬盘,吞吐量小。本身不支持负载均衡,需要loadbalancer的支持
kafka:用于处于活跃的流式数据,大数据量的数据处理上。以consumer为中心,无消息的确认机制,内部采用消息的批量处理, 数据的存储和获取是本地磁盘顺序批量操作,消息处理的效率高,吞吐量高.采用zookeeper对集群中的broker,consumer进行管理, 可以注册topic到zookeeper上,通过zookeeper的协调机制,producer保存对应的topic的broker信息,可以随机或者轮询发送到broker上, producer可以基于语义指定分片,消息发送到broker的某个分片上。
概括:rabbitmq有消息确认机制,支持消息的可靠传递,支持事务,缺点是本身不支持负载均衡,需要借助第三方软件工具实现。 kafka无消息确认机制,内部采用消息的批量处理,采用zookeeper对集群中的broker,cosumer进行管理,有本身就支持负载均衡,其缺点是kafka是用java和scale语言混合编写的,最终编译完成的程序运行在jvm之上,比较吃内存占用资源。
键入网址: 首先查询dns,查询顺序是浏览器缓存,本地hosts文件,本地dns服务器,ISP服务商,递归查询(根、顶级、权威域名服务器) 获取到目的ip之后,通过数据包封装,传输层生成tcp报文, 网络层添加ip包头(源ip和目的ip), 数据链路层添加mac头部 物理层添加帧头帧尾 路途经由交换机,路由器到达目的服务器,完成tcp三次握手,开始建立链接进行通信。
简单概括:dns解析,tcp连接三次握手,发送http请求,服务器处理请求并响应,浏览器解析响应并渲染,tcp四次挥手断开
iptables的四表五链: filter表可以管理input/forward/ouput链 nat表可以管理prerouting/input/output/postrouting链 mangle表用于对对数据包内容进行修改、TTL、Qos等 raw表用于对数据包的跟踪状态进行修改
SNAT用的是POSTROUTING链,DNAT用的是PREROUTING链
linux开机大致启动流程:加载BIOS进行POST硬件自检,读取MBR分区信息(UEFI+GPT),根据启动顺序确定启动的设备,GRUB引导(用于多系统启动,属于BootLoader中的一种),加载内核镜像/boot,运行INIT程序(如果是centos6则会读取/etc/inittab设置启动级别,/etc/rc.d/rc.local下的内容,如果是centos7systemd管理的,则会读取/lib/systemd/systemd),执行/bin/login程序。
sql相关: