Kafka-ELFK分布式日志收集
Kafka + ELFK分布式日志收集
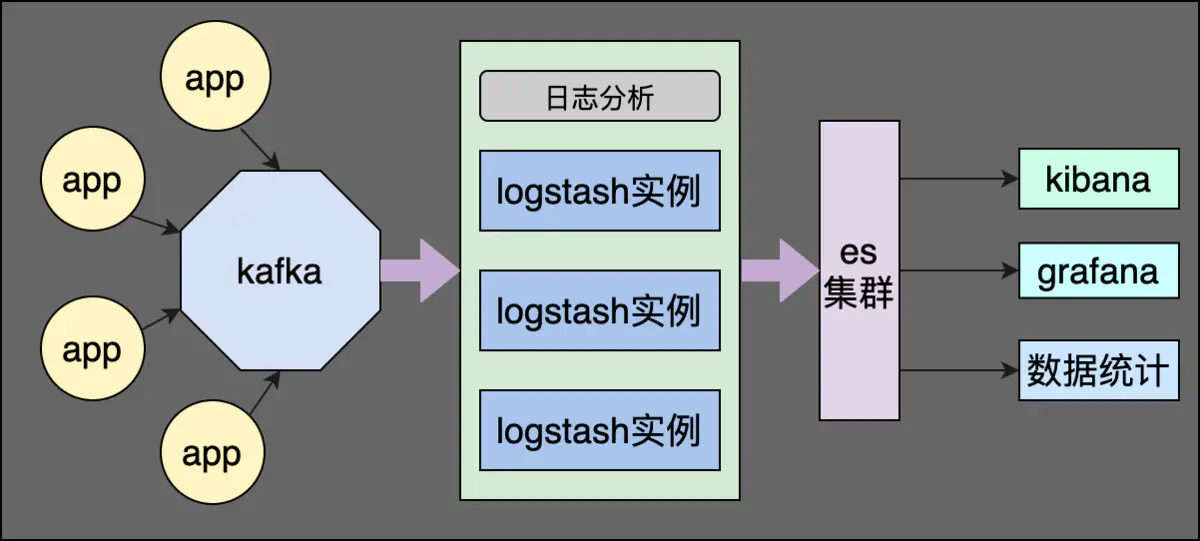
Filebeat —> Kafka —> Logstash —> ES Cluster —> Kibana/Grafana
使用背景
由于ELFK的局限性,随着 Beats 收集的每秒数据量越来越大,Logstash 可能无法承载这么大量日志的处理。虽然说,可以增加 Logstash 节点数量,提高每秒数据的处理速度,但是仍需考虑可能Elasticsearch无法承载这么大量的日志的写入。此时,我们可以考虑 引入消息队列 (Kafka),进行缓存。
Filebeat —> Kafka
# vim /usr/local/filebeat-7.7.1-linux-x86_64/filebeat.ymlfilebeat.inputs:- type: log paths: - /usr/local/apache-tomcat-9.0.34/logs/tomcat_access_log.*.log
output.kafka: # initial brokers for reading cluster metadata #hosts: ["kafka1:9092", "kafka2:9092", "kafka3:9092"] hosts: ["172.16.1.131:9092"] # message topic selection + partitioning # topic: '%{[fields.log_topic]}' topic: tomcat-log partition.round_robin: reachable_only: false启动 Kafka
这里为了方便起见,我使用docker-compose脚本来进行快速部署,脚本内容参见[使用 docker-compose 部署 Kafka](../Kafka/使用 docker-compose 部署 Kafka.md)
Logstash —> ElasticSearch
# vim /usr/local/logstash-7.7.1/config/kafka2es.confinput { kafka { codec => "json" topics => ["tomcat-log"] bootstrap_servers => "172.16.1.131:9092" auto_offset_reset => "latest" group_id => "logstash-g1" }}output { elasticsearch { hosts => "http://172.16.1.131:9200" index => "filebeat_%{[fields][log_source]}-%{+YYYY.MM.dd}" }}